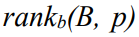[논문 리뷰] A New Method To Index And Store Spatio-temporal data
rlatotquf452024. 10. 10. 14:50
728x90
반응형
저자:
Guillermo de Bernardo, Departamento de Computación, Universidade da Coruña, A Coruña, Spain, gdebernardo@udc.es
Ramón Casares, Departamento de Computación, Universidade da Coruña, A Coruña, Spain, ramon.casares@udc.es
Adrían Gómez-Brandón, Departamento de Computación, Universidade da Coruña, A Coruña, Spain, adrian.gbrandon@udc.es
José R. Paramá, Departamento de Computación, Universidade da Coruña, A Coruña, Spain, jose.parama@udc.es
초록
기존의 시공간 데이터베이스는 대용량의 위치 데이터가 많은 공간을 차지해 이를 디스크를 통해 저장하고. 이 때문에 쿼리 성능이 저하되는 문제가 있음.
이 논문의 방법은 K2-tree를 기반으로 특정 영역의 모든 객체의 위치를 스냅샷으로 저장하고 두 스냅샷 사이의 상대적 이동을저장하는 로그로 기록함. 데이터들을 정수값으로 인코딩하여 공간을 절약하고, 절약한 공간을 기반으로 메인 메모리 내에서만 관리함으로써 빠르고 효율적인 쿼리 처리를 가능하게 함.
주요 기능
특정 시간에 객체 위치 찾기 쿼리
시간 슬라이스 쿼리
주어진 시간에 특정 영역에 존재하는 객체 정보
시간 간격 쿼리
주어진 시간 “간격” 동안 특정 영역에 존재했던 객체 정보
기존 연구 방법
3DR-Tree
시간 축을 공간 좌표와 결합해서 객체의 위치를 선분으로 표현.
시간 간격 쿼리에서는 효율적이지만, 특정 시간 쿼리에서는 비효율적.
RT-Tree
R-Tree 노드에 시간 정보를 추가한 구조.
R-tree는 공간을 중심으로 MBR 영역으로 분할하여 저장.
공간 중심의 자료구조이므로 시간 관련 쿼리에서 비효율적.
HR-Tree
각 시간에 대해 R-tree를 생성하고 이들 간의 겹침을 고려해서 저장.
시간 관련 쿼리에서 성능이 뛰어나지만, 공간 비용에서 매우 비효율적
SEST-Index
특정 시간에 객체의 상태를 나타내는 스냅샷과 로그를 결합해서 궤적을 저장하는 구조.
이 논문에서는 SEST-Index 방법과 유사하게 스냅샷과 로그를 사용하지만, 전통적인 데이터 구조를 사용하는 SEST-Index 와 달리, 압축 데이터 구조를 통해 메인 메모리에서 사용할 수 있는 방법을 제시함.
데이터 구조
그림 1
객체 식별자들의 정보(정수)를 나타내기 위해 K2-tree의 구조를 사용
기존 K2-tree의 경우, 내부 노드의 값을 나타내는 T 배열에서 서브 행렬에 1이 있으면 해당 노드에 1을 할당하고, 1이 없으면 0을 할당.
이 구조를, 서브 행렬에서 “객체”가 존재하면 노드에 1을 할당, 객체가 존재하지 않으면 0을 할당.
이 구조를 통해 T와 L 배열을 나타내면 다음과 같음.
그리고, 특정 객체가 어느 셀에 위치한지, 그리고 특정 셀에 어떤 객체들이 있는지 확인하는 쿼리를 보기 전에 알아야할 연산법과 데이터 구조들을 알아보자.
rank, select 연산
: 비트 배열 B에서 p 번째 위치까지 ‘b’ 값이 나온 “횟수” 반환
:비트 배열 B에서 n번째 ‘b’값이 나타난 “위치(인덱스)” 반환.
Permutation (순열) 구조
순열 구조는 perm 배열의 인덱스(위치값)와 배열 값으로 객체 간의 순서를 나타냄.
순열 구조를 통해 객체의 위치를 찾는 시간을 상수 시간에 처리가능.
그림 1에서의 객체 식별자들을 perm 배열로 나타내면 다음과 같다.
π 연산과 π ^(-1) 연산
π연산 : 순열 배열에서 특정 위치에 어떤 값이 있는지 반환
π (3) = 7
π -1 연산 : 순열에서 특정 값의 위치를 반환.
π^(-1) (3) = 4
순열 배열을 그래프로 나타내면 다음과 같이 순환이 생김을 알 수 있음.
π^(-1) (3) 연산을 수행하기 위해서
perm 배열의 3번째 위치부터 시작한다.
3을 가리키는 객체를 찾을 때 까지 순환을 탐색해서 4을 찾을 수 있다.
즉 3 -> 7 -> 8 -> 1 -> 4의 순서대로 탐색한 후 4를 반환한다.
그런데 만약 객체 식별자가 n개가 있고 순환의 길이가 n이라면, 순환 구조를 사용하는 이점이 없기 때문에 탐색 시간이 길어짐.
따라서 sampled와 rev_link 라는 두개의 추가적인 배열을 사용.
두 배열은 순환을 통해 객체를 탐색할 때 모든 순환을 돌지 않고 지름길을 통해 탐색 시간을 줄여주는 역할을 함.
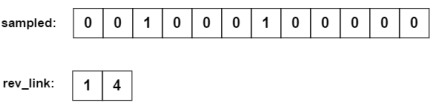
sampled와 rev_link
sampled : 순환 내의 특정 위치를 샘플링해서 해당 위치(배열의 인덱스)에 지름길의 존재를 저장하는 배열.
rev_link : 지름길을 통해 어느 위치로 가야하는지 도착점을 저장하는 배열
이를 그림으로 나타내면 다음과 같다.
이제 다시 지름길을 통해 π (-1)(3) 연산을 수행하면
우선 perm 배열의 3번째 위치부터 시작 (7번 객체).
그런데 sampled의 3번째 값에 1이 있음을 확인 (즉 지름길이 존재함)
지름길이 있음을 확인하고, rev_link에서 해당 값인 1을 통해 perm에서 인덱스 7로 이동하는 것이 아닌, 인덱스 1로 이동.
데이터 저장 구조
앞서 서술했듯이 저장하는 데이터는 스냅샷과 로그 두 가지 데이터 구조를 사용함.
스냅샷 : 주어진 시간 순간에 모든 객체의 전체 위치를 저장
로그 : 두 스냅샷 사이의 객체들의 상대적인 이동 저장
스냅샷 데이터 구조
Q 배열 : k2-tree를 통해 나타낸 비트맵에서 해당 셀에 어떤 객체들이 포함되어 있는지 알기 위해 사용하는 배열.
perm 배열과 일치하게 정렬된 비트맵으로, 비트가 0이면 해당 객체가 특정 셀의 마지막 객체임을 나타내고, 1이면 추가적인 객체들이 존재함을 나타냄.
예를 들어, L 배열(잎)이 0101이고 첫 번째 1이 나타내는 셀에 객체 식별자 10과 30이, 두 번째 1이 나타내는 셀에 객체 식별자 25, 28, 29가 포함되어 있다고 가정하면
여기서 첫 번째 0은 객체 식별자 30이 첫 번째 셀의 마지막 객체임을 나타내고, 두 번째 0은 객체 식별자 29가 두 번째 셀의 마지막 객체임을 나타냄.
특정 셀의 객체들을 찾는 방법
위 그림의 행렬에서 (3, 3)에 위치한 셀의 객체들을 찾는 방법에 대해 단계별로 알아보자.
T와 L 배열을 통해, (3,3)이 위치한 잎 노드를 탐색하면 해당 셀( L 배열의 4번째)의 값이 1이므로 객체가 존재함을 알 수 있음.
잎 노드 이전에 있는 객체가 있는 잎의 수를 계산하기 위해 k = rank1(L, p-1) [ p : L에서 해당 잎의 위치] 를 계산한다. 이 경우 p의 값은 4이므로, k = rank1(L,3) = 1. 즉, 해당 잎 이전에 객체가 있는 잎 노드가 하나 있다는 의미.[(2,2)에 객체가 있는 셀 하나 존재]
그리고 앞서 계산했던 k값이 1이므로, 이전 잎이 끝나는 위치를 찾기 위해 select0(Q,k) = 1 이 나온다. 이 값은 찾고자 하는 잎 노드의 바로 이전 잎의 마지막 위치를 나타내므로 1을 더해 2 값을 얻는다.
이제 perm 배열을 통해 (2)를 통해 7을 얻어 첫번째 객체를 얻는다.
Q 와 P 배열을 순차적으로 탐색하며 Q 배열의 값이 0에 도달할 때 까지(0인경우, 해당 잎의 마지막 객체) perm배열에서 연산을 통해 객체 값을 얻음.
최종결과로 (3,3)에 7과 3이 있음을 알 수 있음.
특정 객체가 어느 위치에 있는지 찾는 법
위 그림에서 객체 3이 어느 셀에 위치하는지 찾는 방법에 대해 단계별로 알아보자.
π (-1) 연산을 통해, 객체 3이 perm 배열에서 4번에 위치함을 알 수 있음.
이때, sampled 배열과 rev_link 배열을 통해 빠른 탐색을 이용함.
Q 배열에서 rank0(Q,k-1)를 통해 이 위치 이전까지 0의 개수를 세어 y = 1의 값을 얻음.